0x01 题目
附件📎:attachment.rar
0x02 解题
下载下来附件,解压之后发现是几千张二维码:
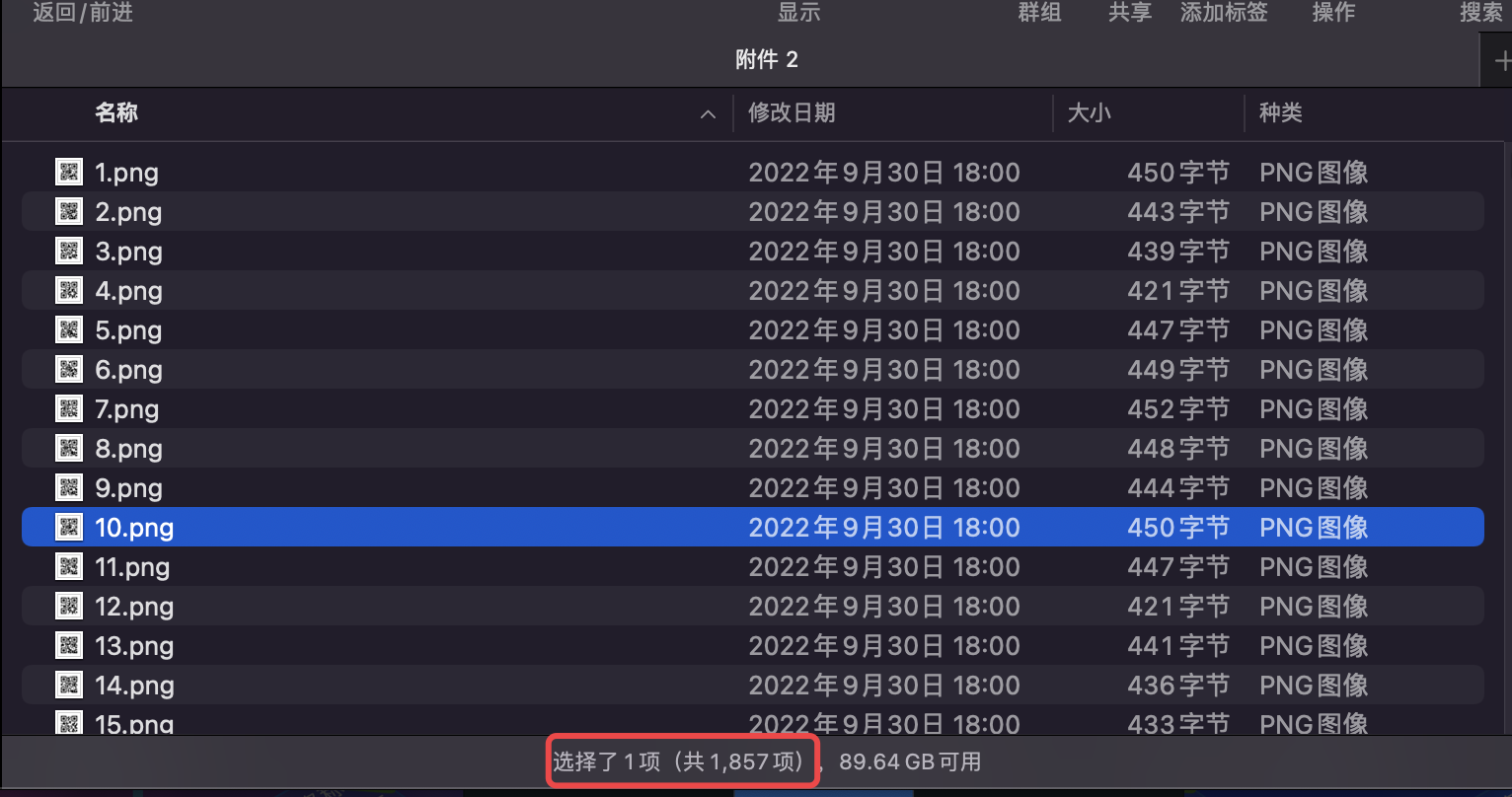
手动一个一个扫肯定是不可能的了,用python里面的pyzbar包进行自动扫码。
1
2
3
| import os
import cv2 as cv
from pyzbar.pyzbar import decode
|
这里遇到了一个坑,os.listdir读取的文件夹里面的图片是乱序的,最后得出来的编码也是乱序,导致在这里卡了一会儿。
需要进行排序:
1
| list1 = sorted(os.listdir(image_path),key = lambda x:int(x[:-4]))
|
然后发现输出的是一串串base64编码,直接把所有base64丢到base64解码器里面是解不出来的,因为里面穿插了一些摩斯密码。
摩斯密码解密出来的字符都是无用的,所以这些摩斯密码都是干扰你的,需要去除:
1
2
|
qrInfo = qrInfo.replace('.','').replace('-','').replace('/','')
|
然后以=为分界线进行一行一行输出
处理过后的base64编码一共有30行
解码base64之后发现还有一层base64,所以这是双层base64编码,需要解码两次:
1
2
| import base64
debase = base64.b64decode(base64.b64decode(str1)).decode()
|
双层解密之后最后得到的编码如下:
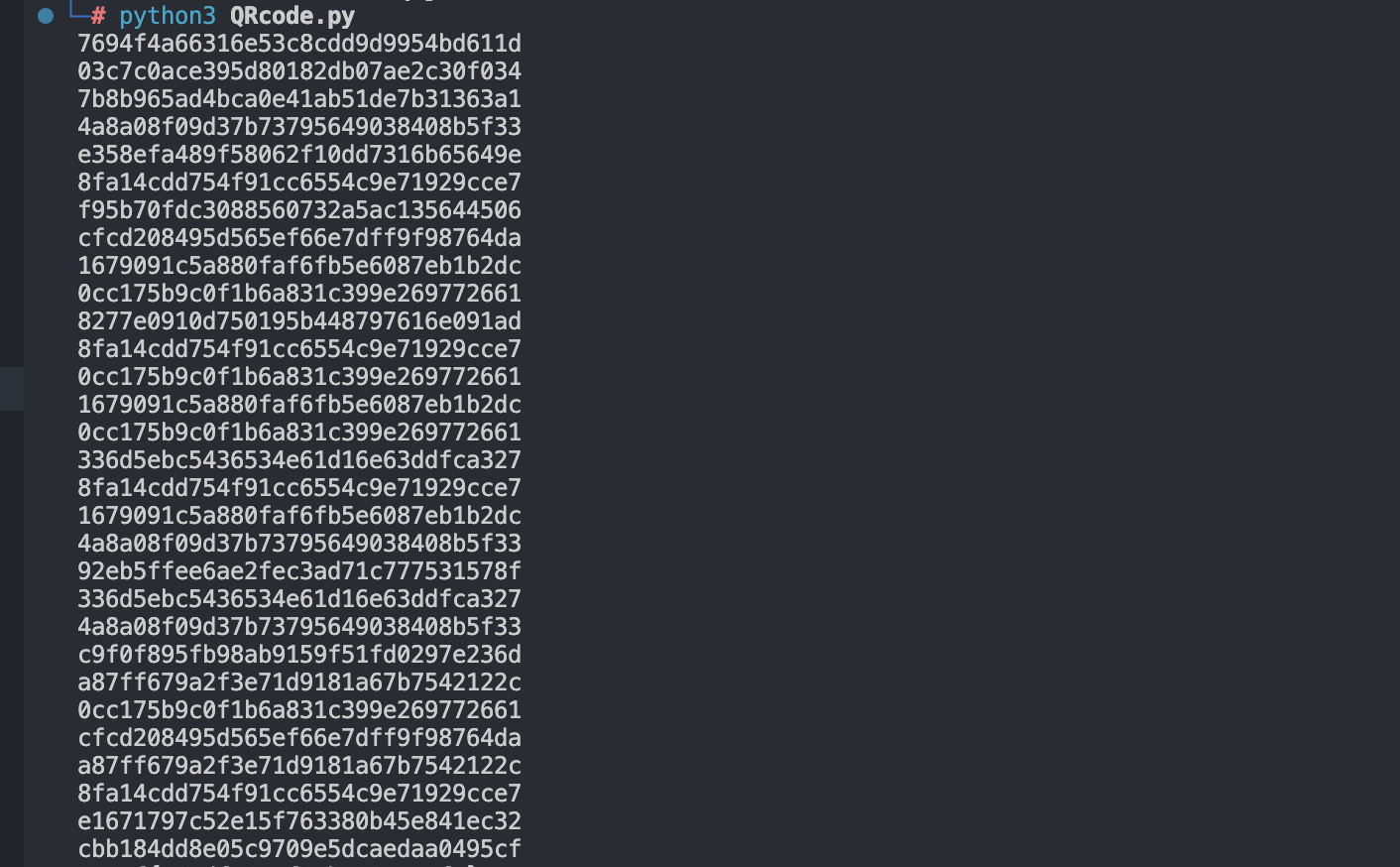
发现都是一些32位的md5,
一个一个去cmd5.com查表,发现一行md5代表一个字母或数字(也可能是“{” “}”)
那么可以通过已知字典进行md5加密一一对比,爆破出flag,所以最终代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| from encodings import utf_8
import hashlib
import os
import cv2 as cv
from pyzbar.pyzbar import decode
import base64
import hashlib
wordlist = 'abcdefghijklmnopqrstuvwxwz0123456789-}{'
m = ''
image_path = './qrcode'
images = []
str1 = ''
list1 = sorted(os.listdir(image_path),key = lambda x:int(x[:-4]))
for f in list1:
images.append(f)
for image in images:
filePath = str(image_path+'/'+image)
img = cv.imread(filePath)
texts = decode(img)
for text in texts:
qrInfo = text.data.decode("utf-8")
if qrInfo == '=':
str1 += ''.join(qrInfo)
debase = base64.b64decode(base64.b64decode(str1)).decode()
for word in wordlist:
md5 = hashlib.md5(word.encode()).hexdigest()
if md5 == debase:
print(f' {debase} = {word}')
m += ''.join(word)
str1 = ''
else:
qrInfo = qrInfo.replace('.','').replace('-','').replace('/','')
str1 += ''.join(qrInfo)
print(m)
|
结果如下:
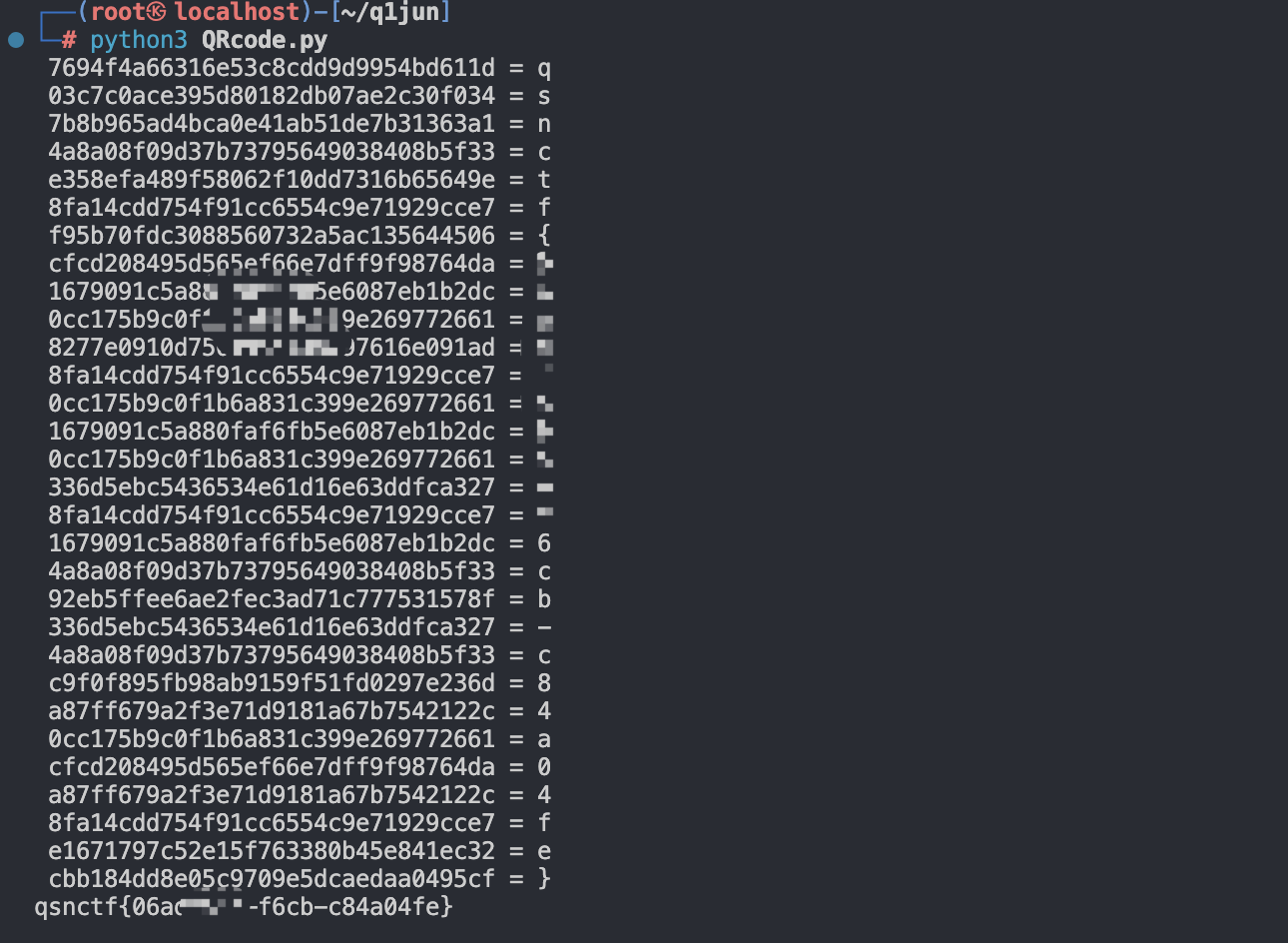
最后发现交不了,经过群友们的友好提示,类UUID格式,这里得到的flag少了一个-,最后结果应该为:
1
| qsnctf{06xxxxxx-f6cb-c84a-04fe}
|
给的题目并不能扫出最后一个-,应该是这题的bug

 Wechat
Wechat Alipay
Alipay

