
如何用Python爬取B站可爱的表情包
如何用Python爬取B站可爱的表情包
0x01 前言
最近在逛B站的时候发现了一套我寻找已久的猫人表情包:
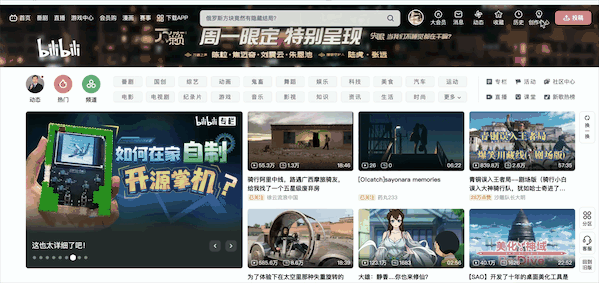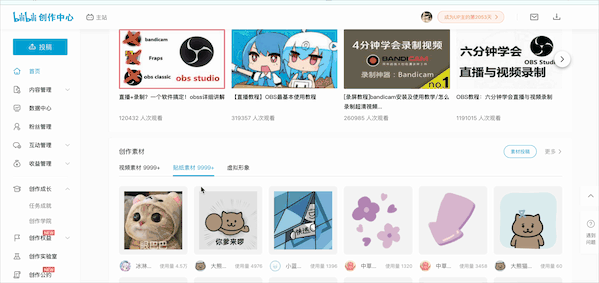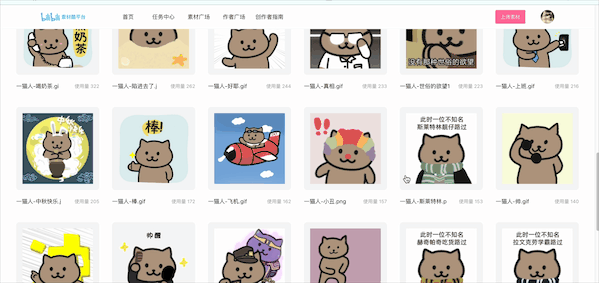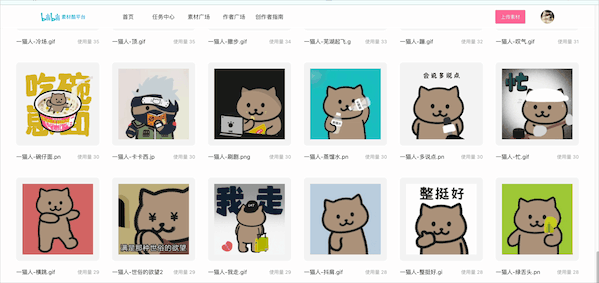
但是当我点进去之后,看到了灰色的下载按钮逐渐起了杀心

简单来说,就是不让你下载,只能下载这个必剪APP才能使用,无奈这个剪辑软件并不适配MacOS系统!可恶
但是这并不影响我下载,只要按下正义的F12,选择元素,找到链接,然后右键保存:
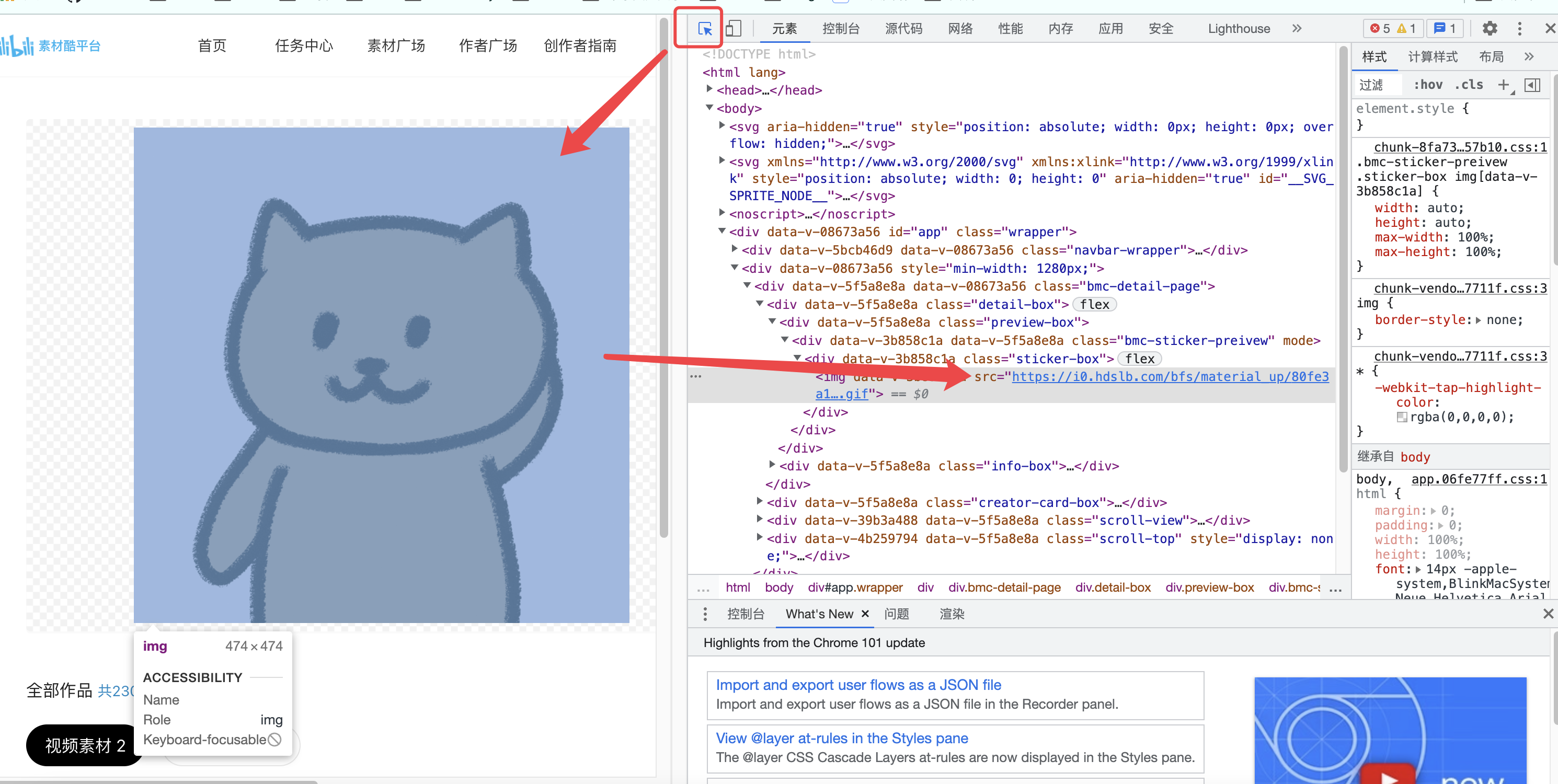

点击这个直接链接之后右键就能下载到本地:

But!,这样虽然可以下载了,但是每个表情都要点进去按F12,一共有228张表情,岂不是要重复228次?
那我们只好写一个正义的爬虫来帮我下载了。
0x02 思路1
由于这个网站是动态加载的,我们需要做更多的操作。
利用selenium和BeautifulSoup4来模拟浏览器操作,获取该页面所有我们需要的数据
1 | from selenium.webdriver.common.keys import Keys #模仿键盘,操作下拉框的 |
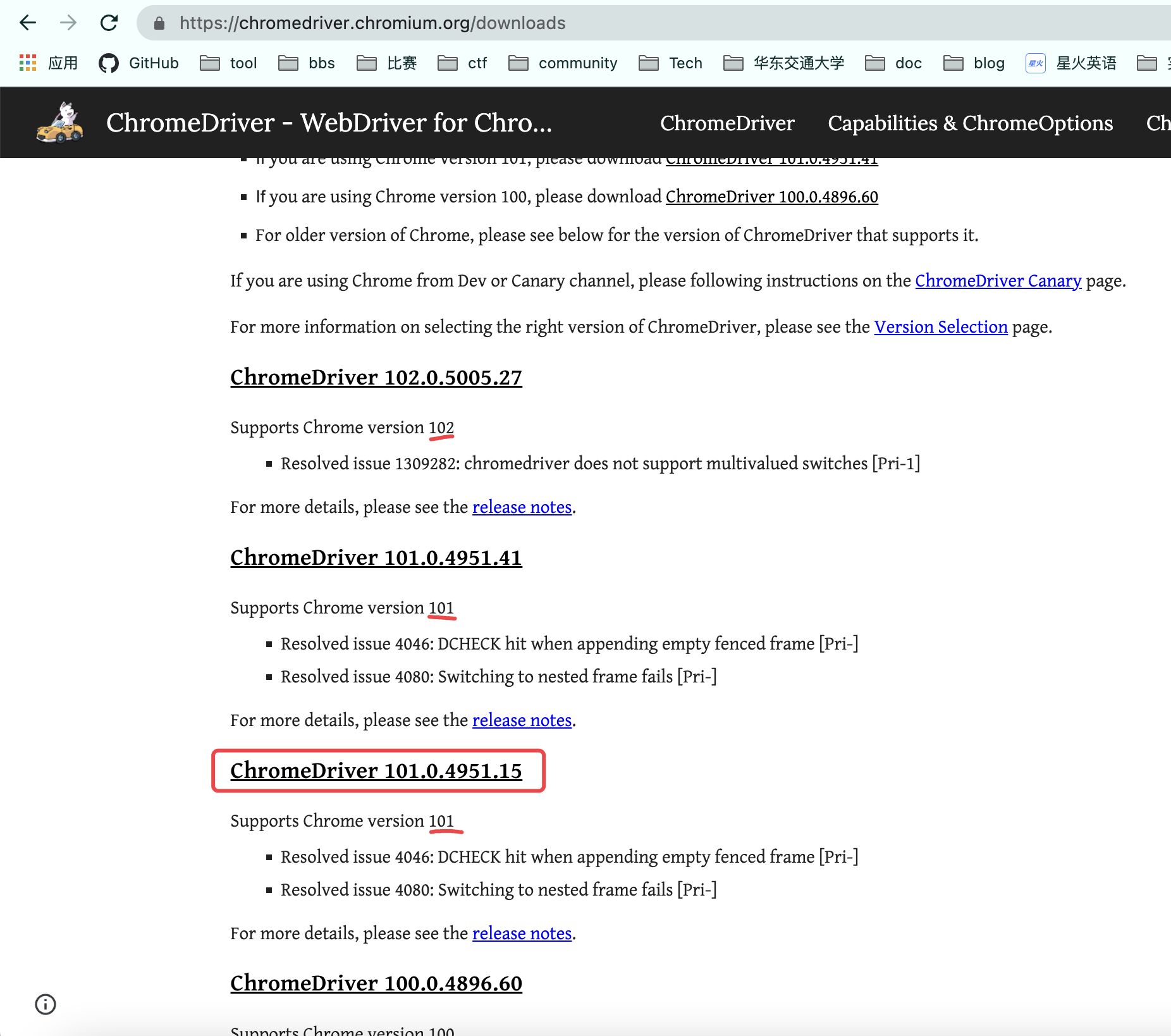
我使用的是Chrome浏览器,需要去下载selenium所需要的对应的浏览器驱动,下载地址如下:
https://chromedriver.chromium.org/downloads
我使用的Chrome版本是101,所以点击如下图所示的地方进入下载:
如果驱动报错就要看报错信息,这里我就是因为版本不兼容报错的,所以我格外说一下😢
具体实现代码如下:
1 | from selenium.webdriver.common.keys import Keys #模仿键盘,操作下拉框的 |
那么问题来了,如下图所示,driver.find_element_by_xpath这个函数已经被弃用了,导致最后获得的数据并不完全。
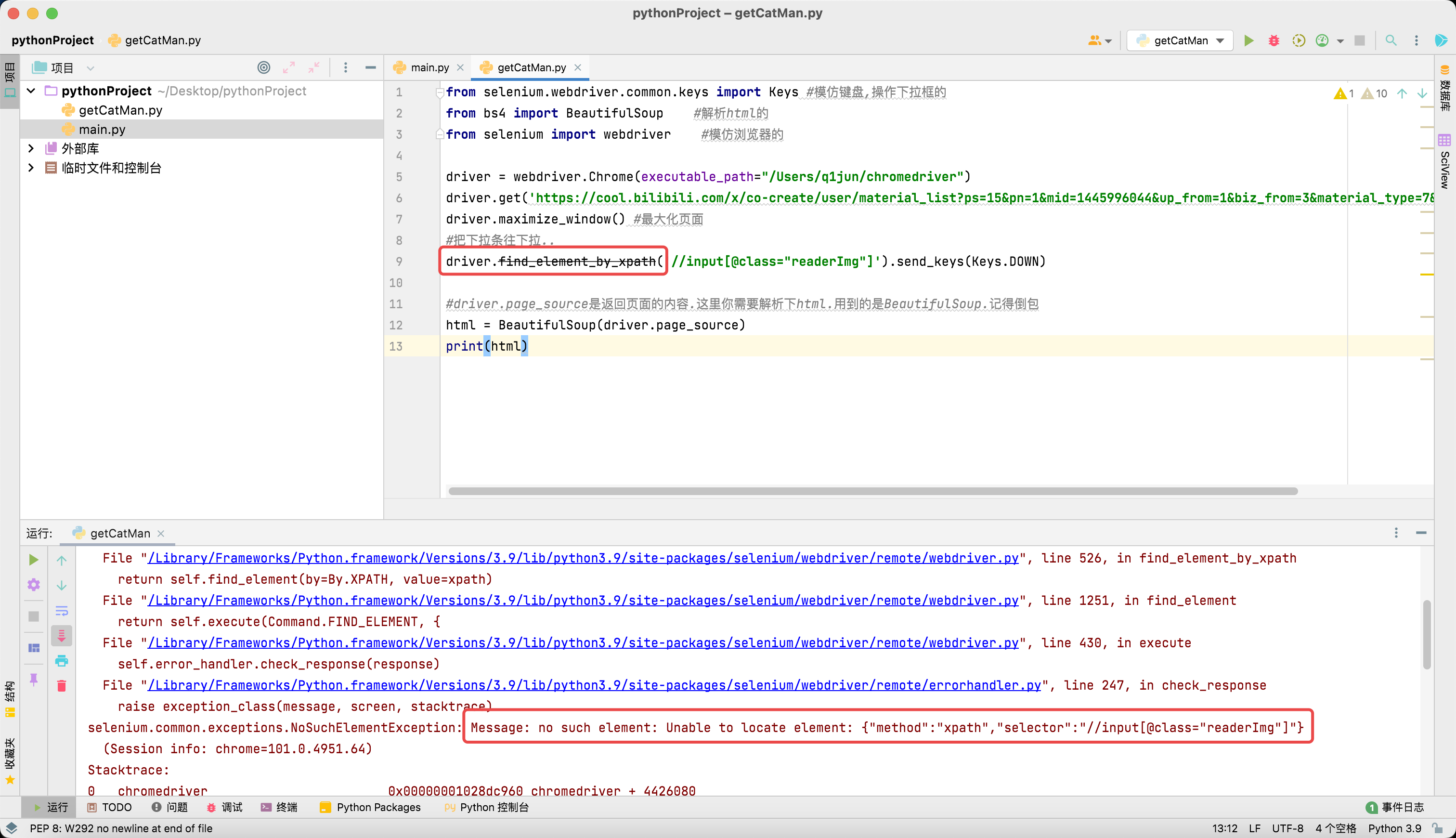
运行结果如下:

才这么几条数据,肯定不是我们所需要的两百多个表情包!可恶,启动Plan B!
0x03 思路2
通过分析页面的请求网址,查看B站是如何请求数据的,我们仔模仿这个请求不就行了?理论存在,实践开始!
首先还是一个正义的F12,选择网络->过滤XDR
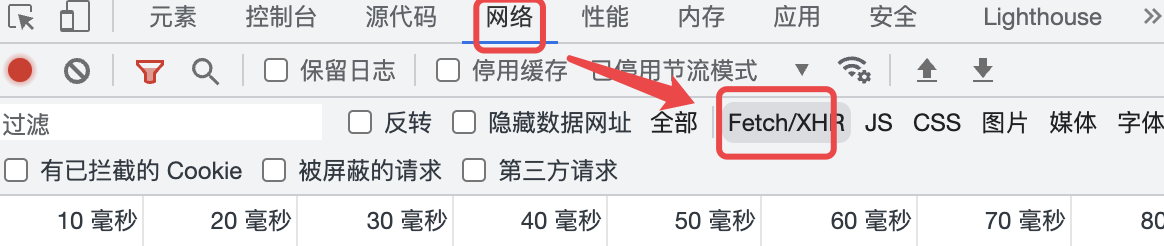
然后我们一直向下划,让前端页面一直发送请求啦取后台数据:
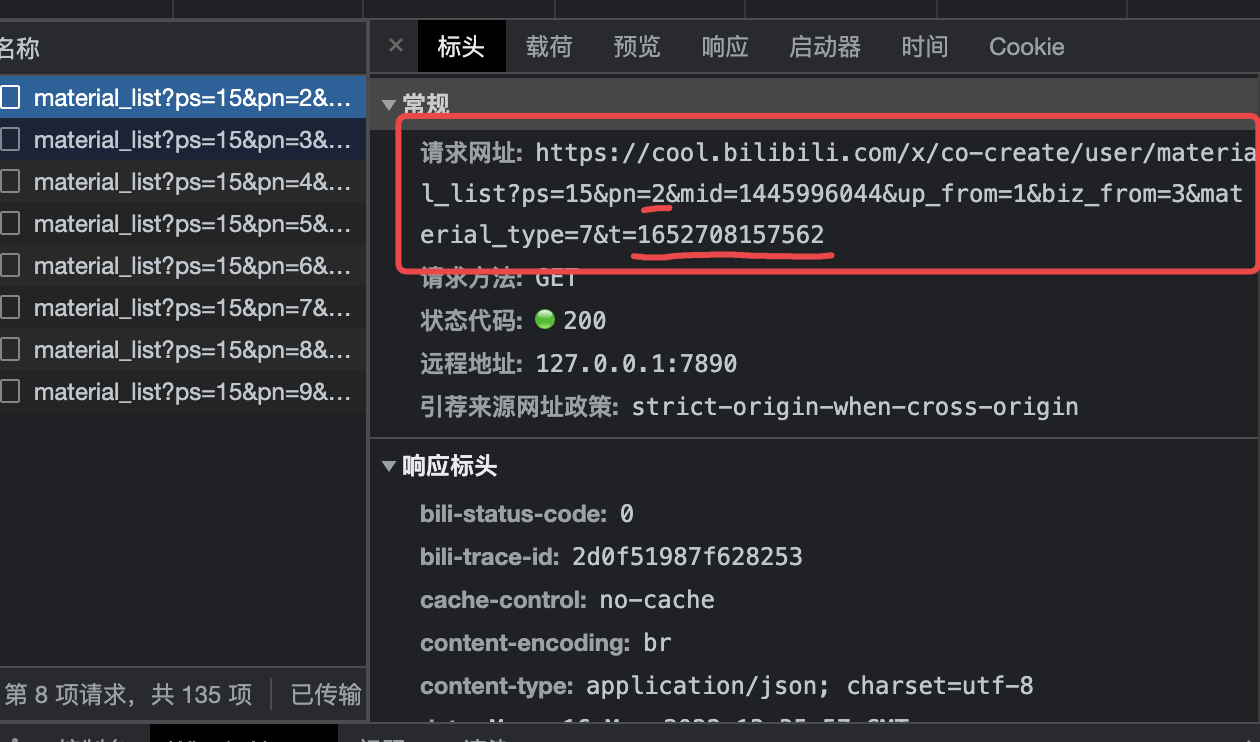
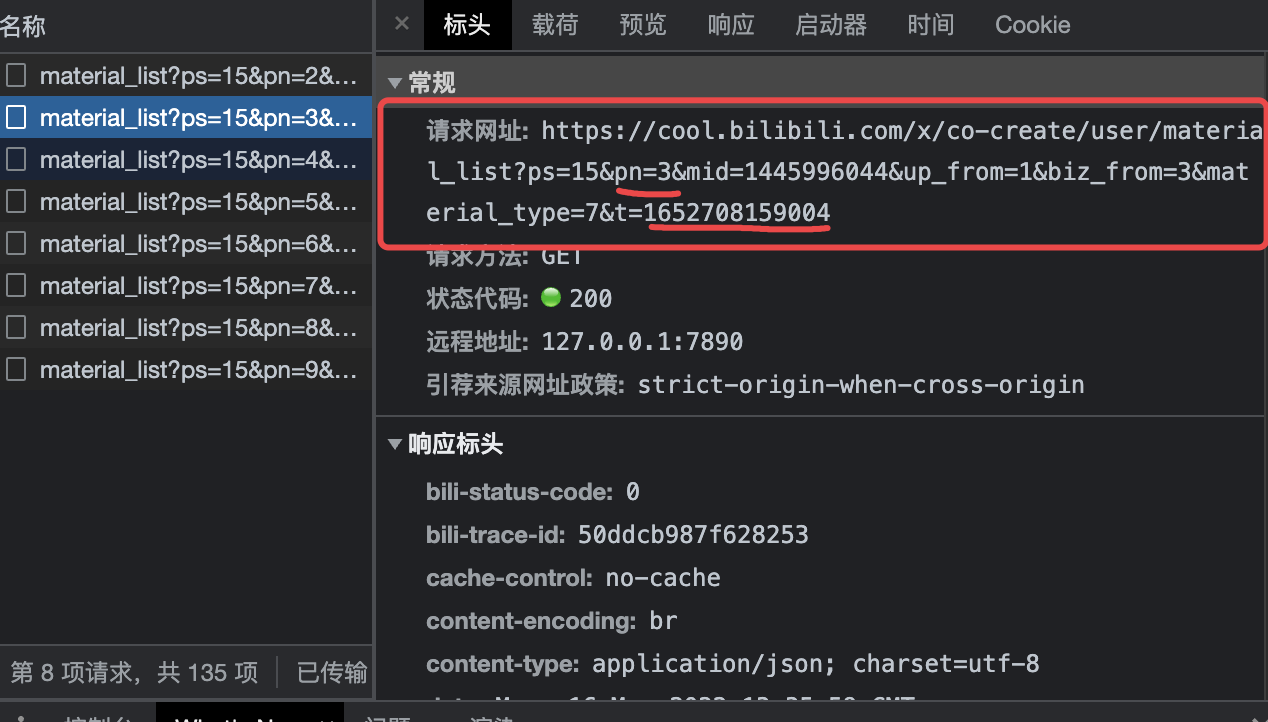
可以看到我标记的两个变量pn和t,只有这两个变量是一直在变化的 (其他的固定参数可以先不用管)。
很显然
pn应该是PageNumber的缩写,标识请求的页数,那t和这串数字1652708159004是什么意思呢?
如果认识时间戳的同学肯定一眼钉真就看出来了,这就是时间戳啊,可以用Python的time包验证一下:
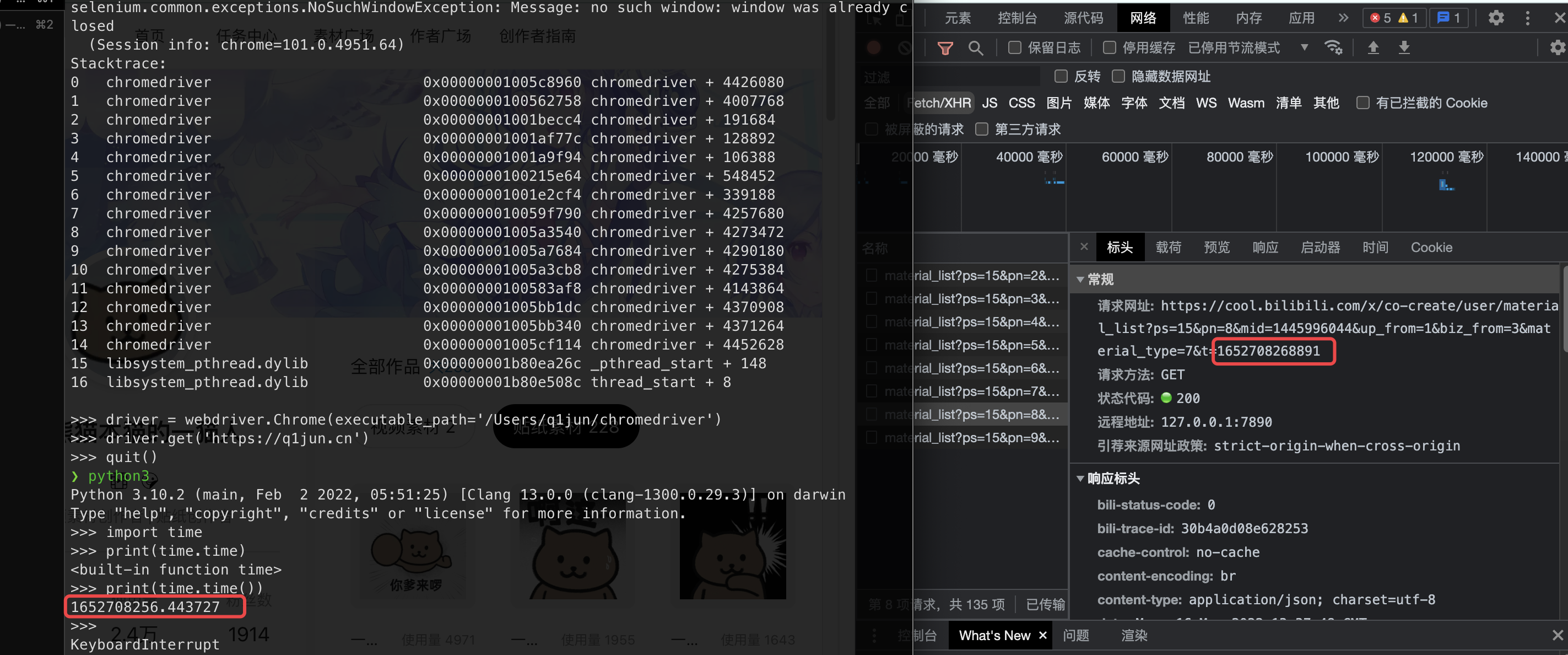
(因为不是同时加载的,所以略有不同)
知道请求参数,那就好办了,直接用requests获取数据打印出来,代码如下:
这里只设置了
pn=2,暂时处理一部分数据,如果一次取太多数据了不好分析。
1 | import requests |
获取的结果如下:
1 | {"code":0,"message":"0","ttl":1,"data":{"material_list":[{"material_id":822876,"material_type":7,"sid":0,"title":"一猫人-真相.gif","cover":"https://i0.hdslb.com/bfs/material_up/7165468d675fa4df192ec861403e7997e9303c34.gif","duration":0,"musicians":"","categories":"","used_count":233,"videopre_url":""},{"material_id":961278,"material_type":7,"sid":0,"title":"一猫人-世俗的欲望1","cover":"https://i0.hdslb.com/bfs/material_up/0b0b9aaa63617ef602f33cea0a83f5e730f4402f.jpg","duration":0,"musicians":"","categories":"","used_count":223,"videopre_url":""},{"material_id":832071,"material_type":7,"sid":0,"title":"一猫人-上班.gif","cover":"https://i0.hdslb.com/bfs/material_up/46376cc652e9113945f9213c2a3a561287d1851b.gif","duration":0,"musicians":"","categories":"","used_count":216,"videopre_url":""},{"material_id":940356,"material_type":7,"sid":0,"title":"一猫人-中秋快乐.j","cover":"https://i0.hdslb.com/bfs/material_up/70e1ca54f83da61532f333b0bf5abfe81ac51686.jpg","duration":0,"musicians":"","categories":"","used_count":205,"videopre_url":""},{"material_id":891899,"material_type":7,"sid":0,"title":"一猫人-棒.gif","cover":"https://i0.hdslb.com/bfs/material_up/a49e0c6c8c61bd0db039264e1301d7d53e83534e.gif","duration":0,"musicians":"","categories":"","used_count":172,"videopre_url":""},{"material_id":894317,"material_type":7,"sid":0,"title":"一猫人-飞机.gif","cover":"https://i0.hdslb.com/bfs/material_up/85a2ff51879f8b6c89938145a28f0d599336fe0a.gif","duration":0,"musicians":"","categories":"","used_count":162,"videopre_url":""},{"material_id":931391,"material_type":7,"sid":0,"title":"一猫人-小丑.png","cover":"https://i0.hdslb.com/bfs/material_up/b68b50d6d739d713c152e493924363f3b72f6f6e.png","duration":0,"musicians":"","categories":"","used_count":157,"videopre_url":""},{"material_id":972898,"material_type":7,"sid":0,"title":"一猫人-斯莱特林.p","cover":"https://i0.hdslb.com/bfs/material_up/3d78bd013a0a820d01985dc29ff832a39b0d8944.png","duration":0,"musicians":"","categories":"","used_count":153,"videopre_url":""},{"material_id":830663,"material_type":7,"sid":0,"title":"一猫人-帅.gif","cover":"https://i0.hdslb.com/bfs/material_up/644bf254c17b733653425db528b3b39553599e1a.gif","duration":0,"musicians":"","categories":"","used_count":140,"videopre_url":""},{"material_id":822879,"material_type":7,"sid":0,"title":"一猫人-冲.gif","cover":"https://i0.hdslb.com/bfs/material_up/7be99b8651dd69cc0664bed583a3256f873e20cb.gif","duration":0,"musicians":"","categories":"","used_count":123,"videopre_url":""},{"material_id":867832,"material_type":7,"sid":0,"title":"一猫人-帅醒.png","cover":"https://i0.hdslb.com/bfs/material_up/61dbe0163a0c545892f195d53d8ba001d394751e.png","duration":0,"musicians":"","categories":"","used_count":122,"videopre_url":""},{"material_id":961783,"material_type":7,"sid":0,"title":"一猫人-JOJO承太","cover":"https://i0.hdslb.com/bfs/material_up/451c9d93008bf50dd0005443c74e45dd72b71128.png","duration":0,"musicians":"","categories":"","used_count":121,"videopre_url":""},{"material_id":860578,"material_type":7,"sid":0,"title":"一猫人-跳舞.gif","cover":"https://i0.hdslb.com/bfs/material_up/d4072bef4bd47bedc6051916d93beb256f7c8c6a.gif","duration":0,"musicians":"","categories":"","used_count":121,"videopre_url":""},{"material_id":942980,"material_type":7,"sid":0,"title":"一猫人-赫奇帕奇.j","cover":"https://i0.hdslb.com/bfs/material_up/88ce5ab9891d8a42133c41bdab538e2414b31f2b.jpg","duration":0,"musicians":"","categories":"","used_count":119,"videopre_url":""},{"material_id":972899,"material_type":7,"sid":0,"title":"一猫人-拉文克劳.p","cover":"https://i0.hdslb.com/bfs/material_up/92ed49143c4301c9e8e5af86b85458c0b6675ac5.png","duration":0,"musicians":"","categories":"","used_count":115,"videopre_url":""}],"pager":{"total":228,"pn":2,"ps":15}}} |
分析我们取到的数据,找到我们需要的东西:

通过前面浏览器调试页面的Accept: application/json得知请求到的数据是Json数据。
然后使用json包处理一下得到的数据 (从第17行开始):
1 | import requests |
结果如下:
1 | /usr/local/bin/python3.9 /Users/q1jun/Desktop/pythonProject/scraper.py |
好!没有问题!
浏览器中直接划到最下面,看看有多深多少页。
查看最后一张,一共有16页,最后一张是火箭队.pn:
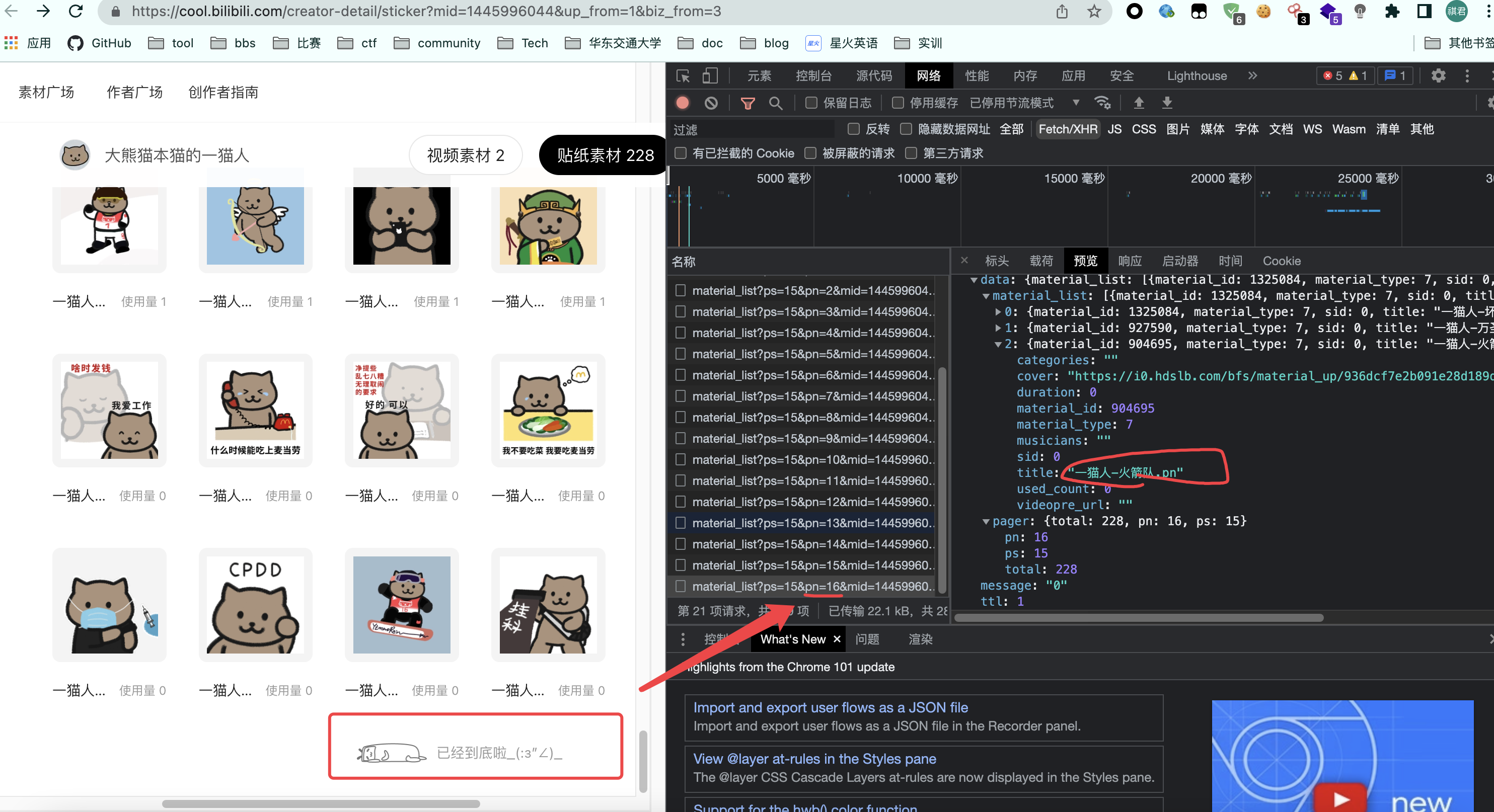
看到这里肯定有人很奇怪,啊为什么是
火箭队.pn不是火箭队.png??这就是另一个问题了,通过查看浏览器中其他数据可以看到表情包的格式有
.png .jpg .gif,但是!可能由于B站的API自身缘故在获得
title这个元素的时候文件后缀有可能少一点,于是出现了这种残缺后缀:
.j,.jp,.jpg还有.和直接省略的!为了保证获取的表情包具有可读性,文件名是一个重要的东西,所以就需要处理一下这个title了。
处理文件名后缀的方法如下:
1 | name = title.replace('一猫人-', '').replace('.png', '').replace('.pn', '').replace('.p', '').replace('.gif','').replace('.gi','').replace('.g', '').replace('.', '').replace('.jpg', '').replace('.jp', '').replace('.j', '') |
大功告成,接下来就是爬取所有表情包了。
爬取所有页面pn=0-16(也许有第0页,不过没关系)的代码:
1 | import requests |
最后通过
os包操作下载到本地的当前目录的source文件夹。
最终代码:
1 | import requests |
最终效果截图:
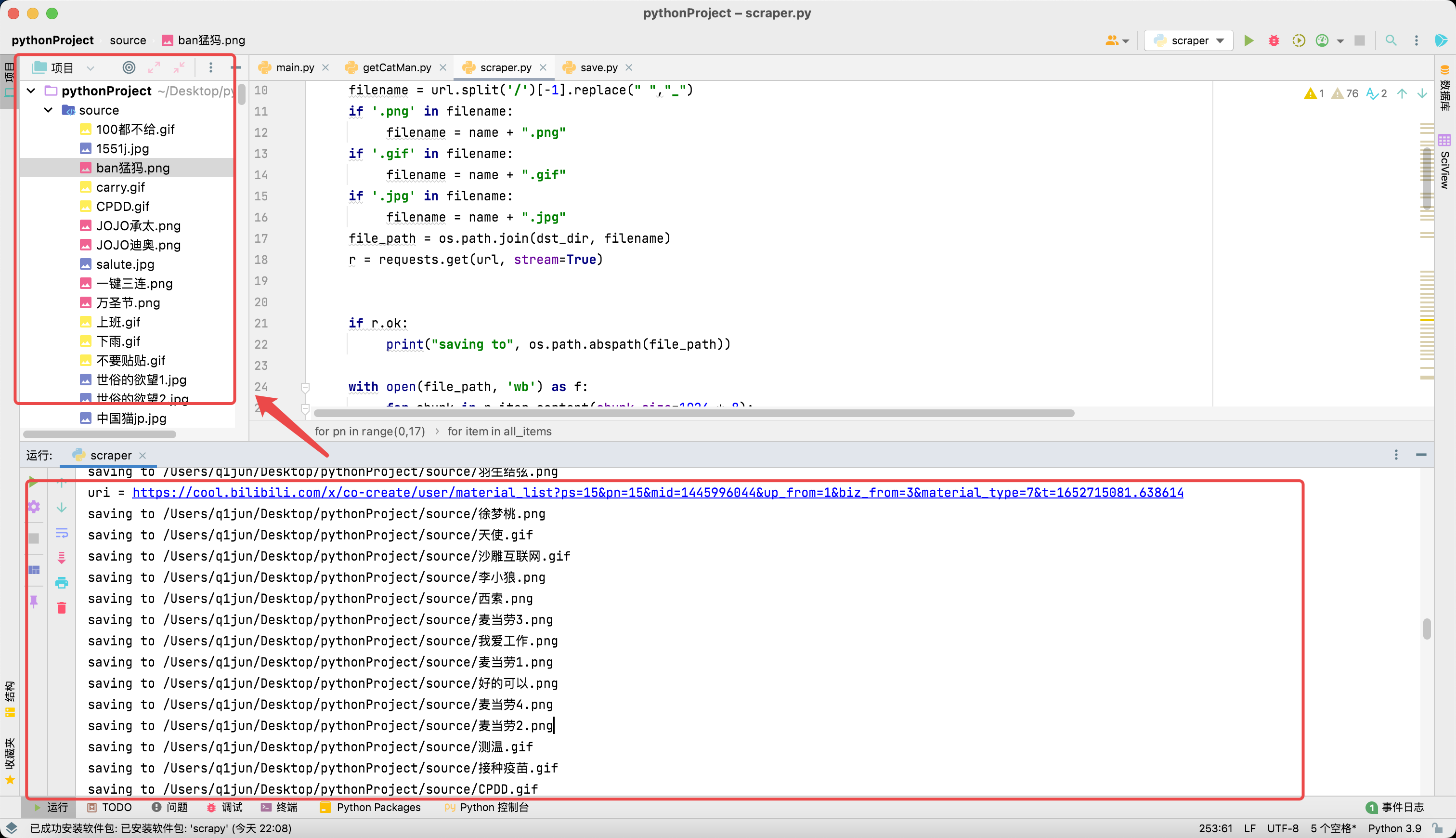
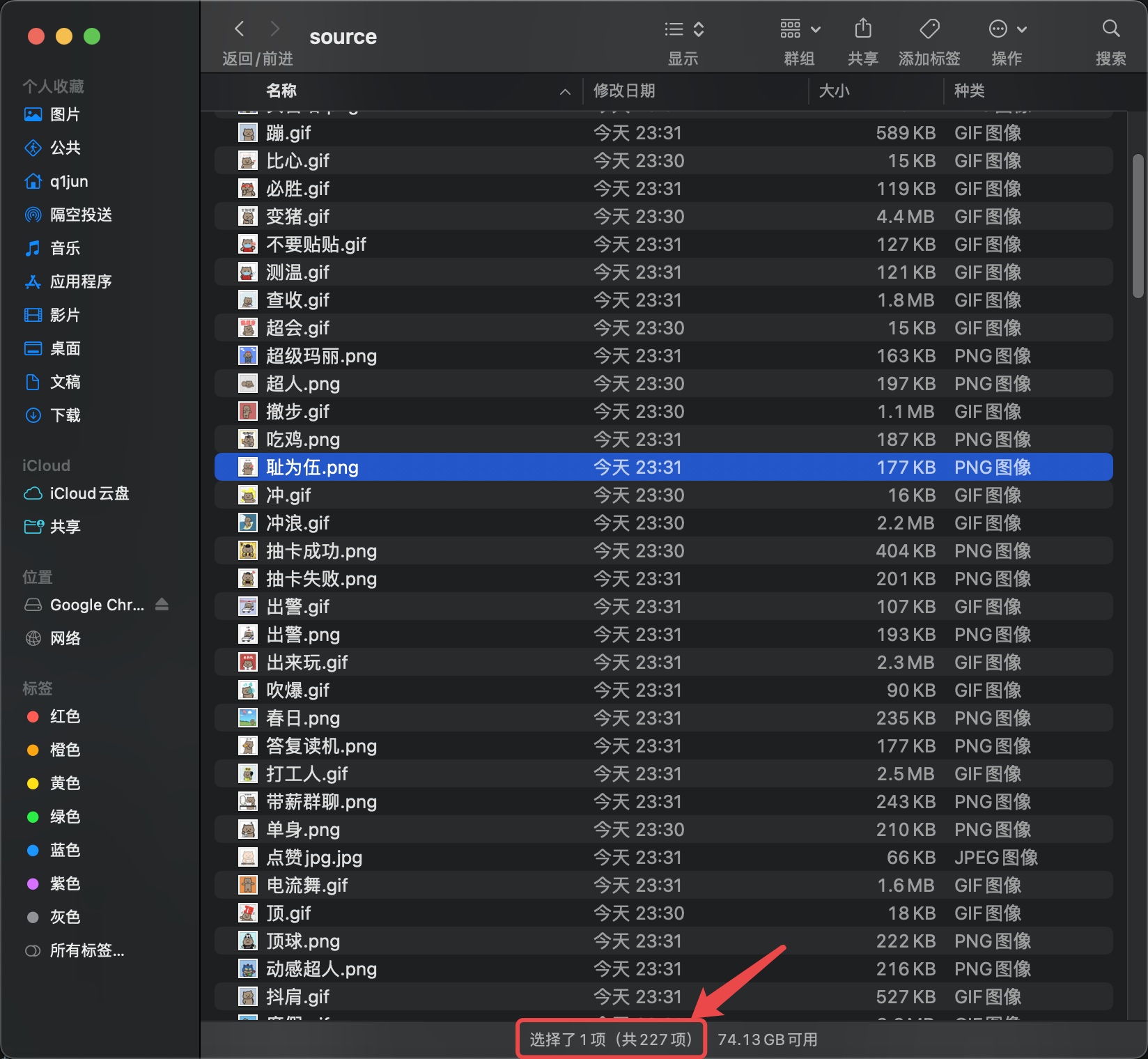
一共227张猫人表情!又可以狠狠的水群了!🥰

下载的表情包
我自己的云: http://cloud.q1jun.cn/s/8GuV (可预览
百度云: https://pan.baidu.com/s/1gPQPjmaAEQodEBGYP_lYvQ 提取码: tnoi
 Wechat
Wechat Alipay
Alipay


